

The most famous quote to characterize python speed is:
It is fast enough
I have used this quote many times, and I still believe that it applies to most circumstances if you throw enough hardware at the problem.
Despite Python being “fast enough” for most applications, a few projects are working on making it even faster. The most well known is PyPy. It has been under active development for nearly a decade and is a production-ready implementation of the CPython API. In the last couple years, a competing project named Pyston has been seeing regular development and improvements. They’re backed by Dropbox who has every reason to prioritize speed (considering that they manage massive amounts of code). They’ve also employed Guido van Rossum, the creator of Python, since 2012.
Both Pyston and PyPy promise to deliver a faster Python Virtual Machine. They are doing so by applying a technique that has proven to be extremely efficient in JavaScript-land. This method is called “Just In Time compilation.”
Here’s what the Pyston team team writes to explain their initiative:
There are already a number of Python implementations using JIT techniques, often in sophisticated ways. PyPy has achieved impressive performance with its tracing JIT; Jython and IronPython are both built on top of mature VMs with extensive JIT support. So why do we think it’s worth starting a new implementation?
In short, it’s because we think the most promising techniques are incompatible with existing implementations. For instance, the JavaScript world has switched from tracing JITs to method-at-a-time JITs, due to the compelling performance benefits. Whether or not the same performance advantage holds for Python is an open question, but since the two approaches are fundamentally incompatible, the only way to start answering the question is to build a new method-at-a-time JIT. Another point of differentiation is the planned use of a conservative garbage collector to support extension modules efficiently. Again, we won’t know until later whether this is a better approach or not, but it’s a decision that’s integral enough to a JIT that it is difficult to test in an existing implementation.
Our Use Case
The hard thing when you try to compare python implementations is to find a use case and understand the side effects. A few months ago, we hired Maciej Fijalkowski to give us a better understanding of what PyPy could do for our Django-based projects. We put together a test suite comprised of a few simple high-level operations that are common in most Django projects:
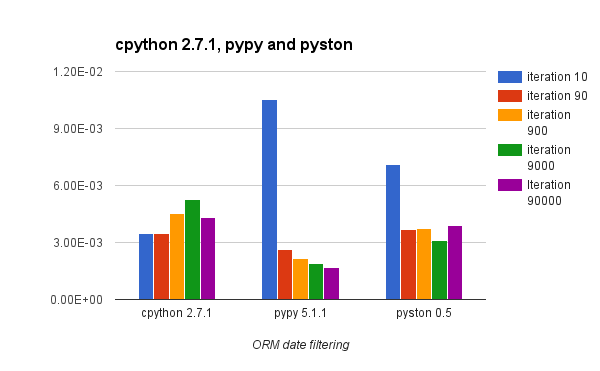
- Building ORM queries that filter on date
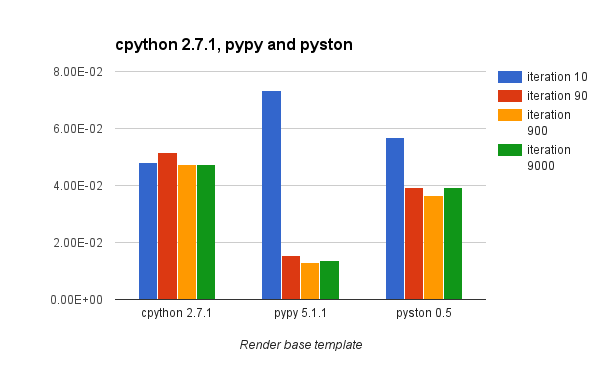
- Render a template tree
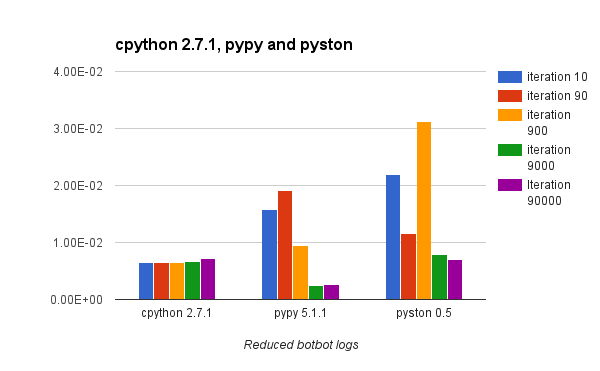
- Combinations of ORM queries that are taken from botbot.me
We built a simplistic “macro” benchmark to understand the disconnect between the stellar benchmark published by PyPy and the mediocre results we were getting ourselves.
Long story short, we learned that PyPy is, in fact, faster for our use case but requires several thousands of iterations to realize the speed improvement. Prior to the JIT “warming up”, PyPy performed significantly worse than the standard CPython implementation.
I decided to run Pyston through the same paces to see how it compared for our use case.
A Word About the Methodology
Django perf tester is a “macro” benchmark that abuses the Django test suite to run the same function a ridiculous number of times (~100,000). We print out the time taken to run it at different points during the iteration cycle. This gives us an idea of the time required to “warm up” before the code optimization kicks in.
I used Docker images pre-built for each Python implementation available at hub.docker.com:
yml@carbon$ (git: master) docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu latest 2fa927b5cdd3 4 days ago 122 MB
pyston/pyston latest eb4e00f6995e 6 days ago 827.3 MB
python latest 7471c1ec292d 2 weeks ago 674.4 MB
python 2.7.11 11a8b7c7f0ca 2 weeks ago 664.9 MB
pypy latest 4adf58248d81 2 weeks ago 688.3 MB
pypy 2-5.1.1 6046115a5c10 2 weeks ago 727.2 MB
I ran this test on my laptop (X1 carbon). As a consequence, all the numbers need to be taken with a grain of salt. My goal was to get an idea of where we’re at for the kind of code I am interested in. I want to see the order of magnitude of requests that need to hit a process before I can get the benefits from these alternative Python implementations.
The benchmark is run like this:
#!/usr/bin/env bash
set -ex
docker run -t --name=django-perf --rm -v "$PWD":/usr/src/django-perf \
-w /usr/src/django-perf pypy:2-5.1.1 \
bash -c "ln -sf /usr/local/bin/pypy /usr/local/bin/python; bash test.sh" > result_test_pypy.txt
docker run -t --name=django-perf --rm -v "$PWD":/usr/src/django-perf \
-w /usr/src/django-perf python:2.7.11 bash test.sh > result_test_python2.7.11.txt
docker run -t --name=django-perf --rm -v "$PWD":/usr/src/django-perf \
-w /usr/src/django-perf pyston/pyston bash test.sh > result_test_pyston.txt
Lies, Damned Lies and Benchmarks
It is impossible to draw a definitive conclusion out of the number shown below. I have seen a huge volatility in performance gain that can be obtained by each JIT Python implementation depending on the use case. To make the problem even harder to solve, speed is not the only criteria that matters as the memory usage might also be drastically different.
pypy
Python 2.7.10 (b0a649e90b66, Apr 28 2016, 08:57:01)
[PyPy 5.1.1 with GCC 4.8.2]
In most benchmarks, you will see comparisons of Python implementations that show how fast each implementation goes after an unknown number of iterations. The result is that CPython is crushed by Python implementations that can JIT the code.
In the results below I try to give you an idea of the performance characteristic of each implementation over time/iterations.
cpython
Python 2.7.11 (default, May 12 2016, 18:24:08)
[GCC 4.9.2] on linux2
pyston
Pyston v0.5.0 (rev c005f5d8de6152c5b6262b244c052e2859c04a68), targeting Python 2.7.7
Conclusion
If your code base has a code path that is run several thousand times, it might be advantageous for you to try a JITed Python implementation as they can provide a substantial boost. Your code might end up being several times faster after a while. However, there is some code, like the Django ORM, that are less JIT friendly and not only require a lot more iterations to get faster, but also start way slower than CPython.
Pyston is still lagging behind PyPy in term of maximum speed increase, but it seems to have a smaller upfront cost on the first iterations.
