


Content-aware chatbots are increasingly common on the web. What used to feel like magic can now be implemented with some know-how and a little code. In this tutorial, we’ll walk you through setting up a Django backend for a chat application powered by Wikipedia content to help start you on your chatbot journey.
To do this, we’ll pull Wikipedia data locally, optimize it by truncating excess information, and ensure minimal operational costs while creating a scalable system. This project showcases how to transform Wikipedia articles into usable data through embeddings and vector databases.
By the end of this guide, you’ll understand how to:
- Process and ingest Wikipedia articles efficiently.
- Use OpenAI’s embedding models to represent text in a way optimized for similarity search.
- Employ FAISS, a vector database, to perform fast lookups and retrieve relevant content for user queries.
Step 1: Setting Up the Django App
We’ll start by modeling Wikipedia articles in Django. The data we’ll use contains fields like id, url, title, and text. Here’s how our models look:
models.py
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=255)
url = models.CharField(max_length=255)
text = models.TextField()
def __str__(self):
return self.title
To make these articles searchable in the Django admin, we’ll add the following:
admin.py
from django.contrib import admin
from .models import Article
@admin.register(Article)
class ArticleAdmin(admin.ModelAdmin):
search_fields = ["title", "text"]
This setup lets you can quickly manage and browse articles via the Django admin panel.
Step 2: Loading Wikipedia Data
We’ll use HuggingFace’s datasets library to load Wikipedia content. A custom management command provides the flexibility to load specific subsets of Wikipedia data, list available datasets, or clear out the articles if needed:
load_wikipedia_articles.py
from django.core.management.base import BaseCommand, CommandError
from datasets import load_dataset
from ...models import Article
class Command(BaseCommand):
help = "Load wikipedia articles using HuggingFace datasets"
def add_arguments(self, parser):
parser.add_argument("--limit", type=int, default=10)
parser.add_argument("--subset", type=str, default="20220301.simple")
def handle(self, *args, **options):
subset_name = options["subset"]
limit = options["limit"]
wikipedia_data = load_dataset("wikipedia", subset_name, split=f"train[0:{limit}]")
articles_to_create = self._prepare_articles(wikipedia_data)
self._save_articles(articles_to_create)
def _prepare_articles(self, wikipedia_data):
articles = []
for row in wikipedia_data:
print(f"{row['id']=}, {row['title']=},{row['url']=}")
articles.append(Article(**row))
return articles
def _save_articles(self, articles):
try:
Article.objects.bulk_create(articles)
self.stdout.write(self.style.SUCCESS(f"Saved {len(articles)} Articles"))
except Exception as err:
self.stdout.write(self.style.ERROR(f"An error occurred while trying to save the articles\nException:\n\n{err}"))
This is how our command will look in our CLI:
python -m django load_wikipedia_articles --list
python -m django load_wikipedia_articles --delete
python -m django load_wikipedia_articles --limit=50 --subset="20220301.simple"
We should now have Articles in the Django admin:
Step 3: Generating and Storing Embeddings
Embeddings represent text as vectors in a multi-dimensional space, allowing us to compare their similarity. We’ll use OpenAI’s embedding API to generate embeddings for each article and store them in FAISS, a high-performance vector database.
Here’s how to create embeddings:
ingest_embeddings.py
import pickle
from django.core.management.base import BaseCommand
from django.conf import settings
from ...models import Article
from langchain.vectorstores.faiss import FAISS
from langchain.embeddings import OpenAIEmbeddings
class Command(BaseCommand):
help = "Ingest Wikipedia articles as embeddings into a FAISS vector database."
def add_arguments(self, parser):
parser.add_argument("--delete", action="store_true")
parser.add_argument("--limit", type=int, default=1)
parser.add_argument("--path", type=str, default="./chat_with_wikipedia.pkl")
def handle(self, *args, **options):
# Logic for embedding articles and saving them into the vector database…
limit = options.get("limit")
path = options.get("path")
if options["delete"]:
self.stdout.write(f"Are you sure you want to delete {path} articles? (yes/no)")
response = input()
if response == "yes":
self._prompt_delete_vector_database(path=path)
article_qs = Article.objects.all()[:limit]
vectorstore = self._populate_vectorstore(article_qs)
self._save_vectorstore(path, vectorstore)
def _prompt_delete_vector_database(self, path: str):
Path(path).unlink(missing_ok=True)
self.stdout.write(self.style.SUCCESS('Vector database deleted.'))
def _populate_vectorstore(self, article_qs):
documents = []
for article in article_qs:
self.stdout.write(f'Starting to process {article.title=}')
try:
title_doc = Document(
page_content=article.title,
metadata={"source": article.url, "title": article.title, "field": "title"}
)
text_doc = Document(
page_content=article.text,
metadata={"source": article.url, "title": article.title, "field": "text"}
)
text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=600, chunk_overlap=100)
documents.extend(text_splitter.split_documents([title_doc, text_doc]))
except Exception as err:
self.stdout.write(self.style.ERROR(f"Error: {article.url}, {article.title}, {err}"))
embeddings = OpenAIEmbeddings(openai_api_key=settings.OPENAI_API_KEY)
return FAISS.from_documents(documents, embeddings)
def _save_vectorstore(self, path, vectorstore):
with open(path, "wb") as f:
pickle.dump(vectorstore, f)
self.stdout.write(self.style.SUCCESS('Vector store saved.'))
This command takes articles from the database, splits them into smaller chunks, generates embeddings for each chunk using OpenAI’s API, and stores them in a FAISS vector database.
You can generate embeddings via the following command:
python manage.py ingest_embeddings --path=./wiki_embeddings.pkl
Step 4: Building the Chat Interface
With the embeddings in place, we can create a conversational retrieval system. This will take user queries, find the most relevant Wikipedia content, and return it as a response.
Here’s how we implement it:
chat_with_wikipedia.py
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
def get_qa_chain():
"""Initialize a ConversationalRetrievalChain for Q&A."""
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
retriever = load_retriever()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
return ConversationalRetrievalChain.from_llm(llm=llm, retriever=retriever, memory=memory)
if __name__ == "__main__":
# Command-line loop for chatting with Wikipedia data…
c = Console()
c.print("[bold]Chat with wikipedia!")
c.print("[bold red]---------------")
qa_chain = get_qa_chain()
while True:
default_question = "Ask wikipedia: what is August?"
question = Prompt.ask("Your Question: ", default=default_question)
result = qa_chain({"question": question})
c.print(f"[green]Answer: [/green]{result['answer']}")
c.print("[bold red]---------------")
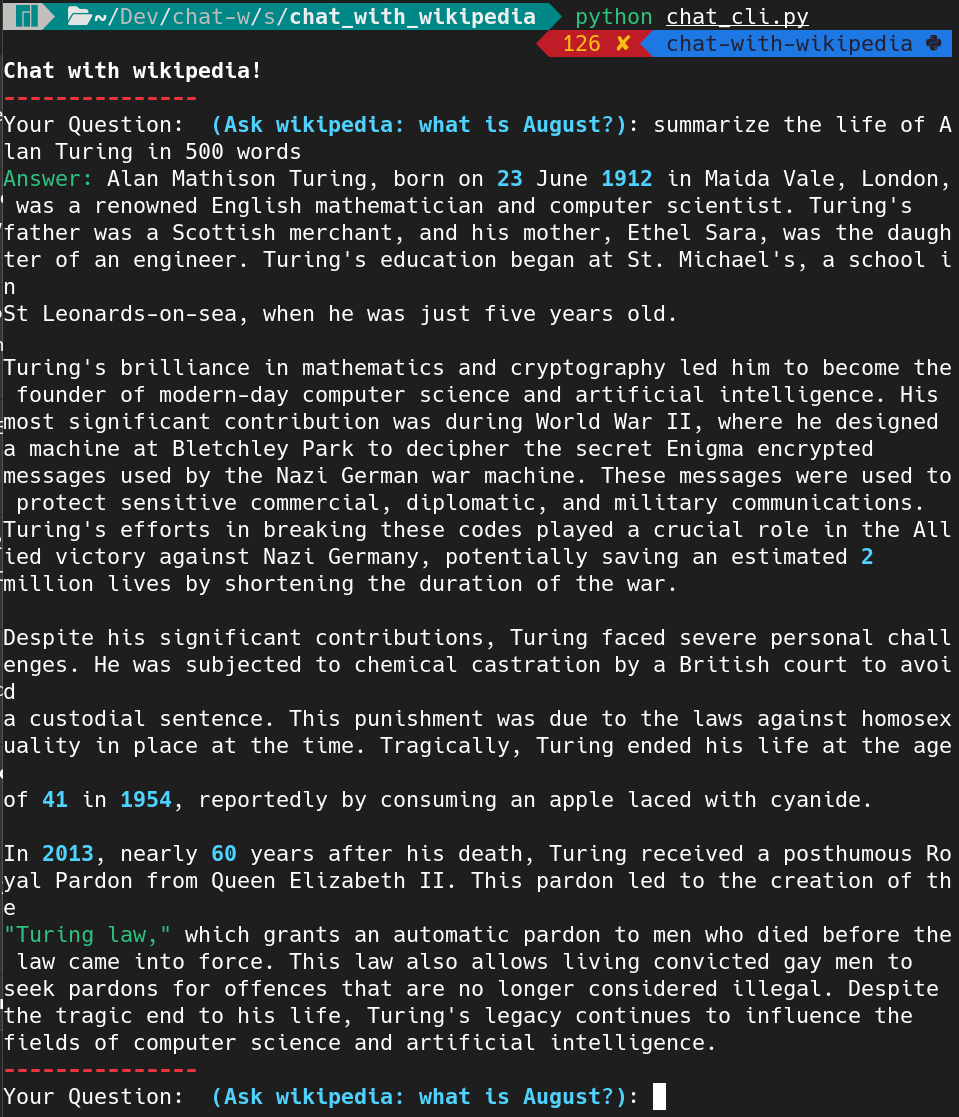
This script initializes a conversational retrieval chain using GPT-4. It loads the vector database (where embeddings are stored), and when a user submits a query, the system retrieves relevant article segments and generates a response.
In summary, it connects the frontend (the chat interface) with the backend (the vector database and embeddings), allowing users to interact with the Wikipedia data seamlessly. You can imagine serving this response in an user-friendly interface.
Here is an example of a command line chat session:
Enhancements and Future Directions
To improve this chat interface, consider the following upgrades:
- Integration with Slack: Move the chat interface to a more interactive platform like Slack.
- Data Structuring: Use language models to structure your vector database better, improving search accuracy.
- Summarization: Automatically generate concise summaries of each article for quicker responses.
- Caching: Cache embeddings and scale horizontally to handle larger datasets more efficiently.
Conclusion
By combining Django, Wikipedia data, and modern NLP tools, you can create a powerful chat backend capable of retrieving meaningful responses. While this project scratches the surface of what’s possible, it lays a solid foundation for further exploration.
