The Build
Premature optimization is the root of all evil.
—Donald Knuth
Building a high-traffic site from scratch is a dangerous undertaking. There are lots of places Django can be optimized and it’s easy to fall into a trap of optimizing things that won’t need it. Trying to do it all grinds productivity to a halt and wastes months or even years of developer time. The key is to separate the optimization you need from the time-wasting optimizations that won’t make a difference.
Your biggest ally in this fight is real-world data. If you are replacing an existing site, looking at the existing data and traffic patterns over a long period is imperative. Knowing how existing users behave on the site will help you identify the hot spots requiring optimization. Saving a single database query on a page that sees a million hits a day is far more important than saving ten queries on a page that only gets one thousand views daily.
In many cases, you won’t have any real-world data to work with but you can create your own. “Soft” launching to a small group of users lets you collect performance data to see where optimization is required. Huge sites like Facebook and Etsy make heavy use of “feature-flippers” that allow them to turn on specific features to a subset of their users. This is discussed further in Launch Planning.
Once you know where the hot spots are in your application, you can start optimizing by taking the easiest and least intrusive steps first (remember, our goal is simplicity). A good load testing environment will give you quick feedback on the effect of your changes and confidence when you’ve done enough optimization. This is discussed further in Load Testing with Jmeter.
Approach
There are a few basic tenets to how we build Django sites that might not seem important now, but make a big difference down the road.
Local Development
A developer should be able to install and run the Django project wherever it is convenient for them: a laptop, virtual machine, docker container, or remote server. Too often we see teams throw their hands up in the air and say their application is too complex for this. In reality, that’s rarely the case. Making the project easily installable will accelerate onboarding new developers and help fight back unnecessary complexity. The local development environment should be configured as closely as possible to production. If you use Postgres on your servers, don’t use SQLite locally. Those subtle differences in your environments can be the source of ugly hard-to-track bugs.
Settings Organization
Some developers like to go crazy with their settings files, building complex file structures or introducing class-based inheritance schemes. Complexity is our sworn enemy. Instead, we try to maintain a simple setup, inspired by the 12 Factor[1] application philosophy.
At the root of our project, we create a settings module. Ideally this will
just be a single file, but once a project gets sufficiently large that approach
tends to be unrealistic. Rather than a one-size-fits-all file, we create a few
sub-modules:
settings.baseThe settings shared amongst all deploys. This should be the largest file of the bunch.settings.deployA few tweaks for deployment such as implementing caching layers that would otherwise inhibit local development. These settings are used for all non-local environments (test, stage, production, etc.)settings.localThis module is not checked into the repo, but used to give Django a default settings module that “just works”. In deploy environments, it would simply be a symlink todeploy.pyand for local development machines, it would be a manually edited file tailored to that developer’s preferences.
Tip
We typically commit a project/settings/local.py.example file that can
be copied to project/settings/local.py as part of the install process.
It contains all the settings necessary to get started with a local install
of the project.
All settings inherit from settings.base so in settings.deploy you might
see something like this:
from .base import *
# wrap the base template loaders with a cached loader for deployment
TEMPLATES[0]['OPTIONS']['loaders'] = [
('django.template.loaders.cached.Loader',
TEMPLATES[0]['OPTIONS']['loaders'])
]
There are a couple problems we still need to solve with this approach:
We don’t want to commit sensitive information such as database password or API keys into our repository.
We need to make some subtle differences to the deploy settings across the different environments (database host, API keys, etc.).
If we were following the 12 Factor philosophy exactly, we’d have our configuration management tool write them out as environment variables and configure the deploy settings to read from those values at startup.
Environment variables are a viable approach, but in practice, they are not without faults. The first issue you’ll encounter is that environment variables are always strings. You’ll probably want to use them for integers, booleans, and lists once in your settings file. This is not a difficult problem to solve, but, if not done correctly, can lead to unexpected issues.
Second, ensuring that the correct environment variables are always picked up whenever your application runs creates a bit more of a challenge. Your application may run via uWSGI or a management command or imported in a custom script or via cron or any number of other scenarios. This typically involves copying the secrets to a number of different locations and formats.
Instead, we prefer a more explicit approach that solves both these issues. Our configuration management tool writes out a single JSON file with all the necessary settings for that environment. Here’s what you might find in a typical one:
{
"DEBUG": false,
"ALLOWED_HOSTS": ["example.com", "www.example.com"],
"DATABASE_URL": "postgres://user:password@host:5432/db_name",
"MEDIA_ROOT": "/srv/site/data/media",
"SECRET_KEY": "iNPREJ4UKrV3njLKmOqPlgVYCwJaHen2ElW5j7QF",
"SOME_API_KEY": "secret-api-key-here"
}
Then, at the top of the deploy.py settings file, you’ll find something like
this:
import json
with open('/srv/project/config.json') as config_file:
CONFIG = json.load(config_file)
CONFIG is just a Python dictionary which is referenced in a few different
ways. For required settings (the app should fail to start if they aren’t
defined), we simply do:
# Required setting
SECRET_KEY = CONFIG['SECRET_KEY']
For optional settings, simply check for the existence of the key first:
# Optional setting
if "SOME_API_KEY" in CONFIG:
SOME_API_KEY = CONFIG['SOME_API_KEY']
And finally, for settings that have a default, but may need to be overridden,
you can take the setting from base.py if the key is not found:
from .base import *
# Setting with default from base.py
SOME_API_KEY = CONFIG.get('SOME_API_KEY', SOME_API_KEY)
One last helpful tip we use to ensure the right settings are used is the
local.py symlink we mentioned above. We modify all the entry-points to the
project (typically manage.py and wsgi.py) to use those settings by
default. This is as easy as:
import os
os.environ.setdefault(
"DJANGO_SETTINGS_MODULE",
"project.settings.local"
)
It cuts down on mistakes and saves the hassle of manually specifying the
settings every time. This technique will not override DJANGO_SETTINGS_MODULE
if the environment variable was already defined, so things still work as
expected if you find the need to change it for some reason. You can find
examples of these techniques in our Django template, django-layout[2].
Be Cautious of Third-Party Apps
One strength of the Django ecosystem is the variety of high-quality reusable applications available on PyPI. Unfortunately, the vast majority of these applications were not written for high traffic scenarios. In many cases, they’ve traded off performance for ease of use and flexibility.
Building your site around a specific library, only to find out it performs like a dog in the real world, can be a massive setback. This is a situation where an ounce of prevention is worth a pound of the cure. You should always evaluate third-party modules before integrating them into your stack. Specific questions to ask:
Does it cover your exact requirements or just come close?
Is it a healthy project?
Does the maintainer have a good track record?
Is it well documented?
Does it have good test coverage?
How is the community (contributors, pull requests, etc)?
Is it under active development?
Are there lots of old issues and pull requests?
How does it perform?
How many database queries will it make?
Is it easy to cache?
Does it have any impact on the rest of your applications?
Does it have a license and is it compatible with your project?
Unmaintained and unstable third-party applications will quickly become a liability to your project. Once you dig through the source code you may discover that you only need a few lines to meet your needs. In that case, pulling in a new dependency might be overkill. Don’t be afraid to copy the techniques you learn and adopt them to your project-specific needs.
Also keep in mind that every dependency you bring into your project is going to use up a small (or not so small) chunk of RAM. It may not seem like much, but over time, with more dependencies, it adds up. As a point of reference, a bare Python interpreter uses a couple megabytes of RAM. We’ve seen production applications that chew up 200+ megabytes. That number then gets compounded by the fact that you’ll be running multiple WSGI instances in production. With RAM often being the limited resource on high-performance servers, keeping things “slim” can save you money as well. For more on this topic, check out Mike Perham’s article, Kill Your Dependencies. It’s Ruby-focused, but is totally applicable to Python as well.
Watching Performance
Out of the box, Django doesn’t give us much insight into what’s happening during the request/response cycle. You’ll want to add some functionality to see the performance characteristics of your pages during development. Django Debug Toolbar[3] is the tool of choice for this work. It will give you a page overlay showing you lots of information including database queries, templates used, timing, and more.
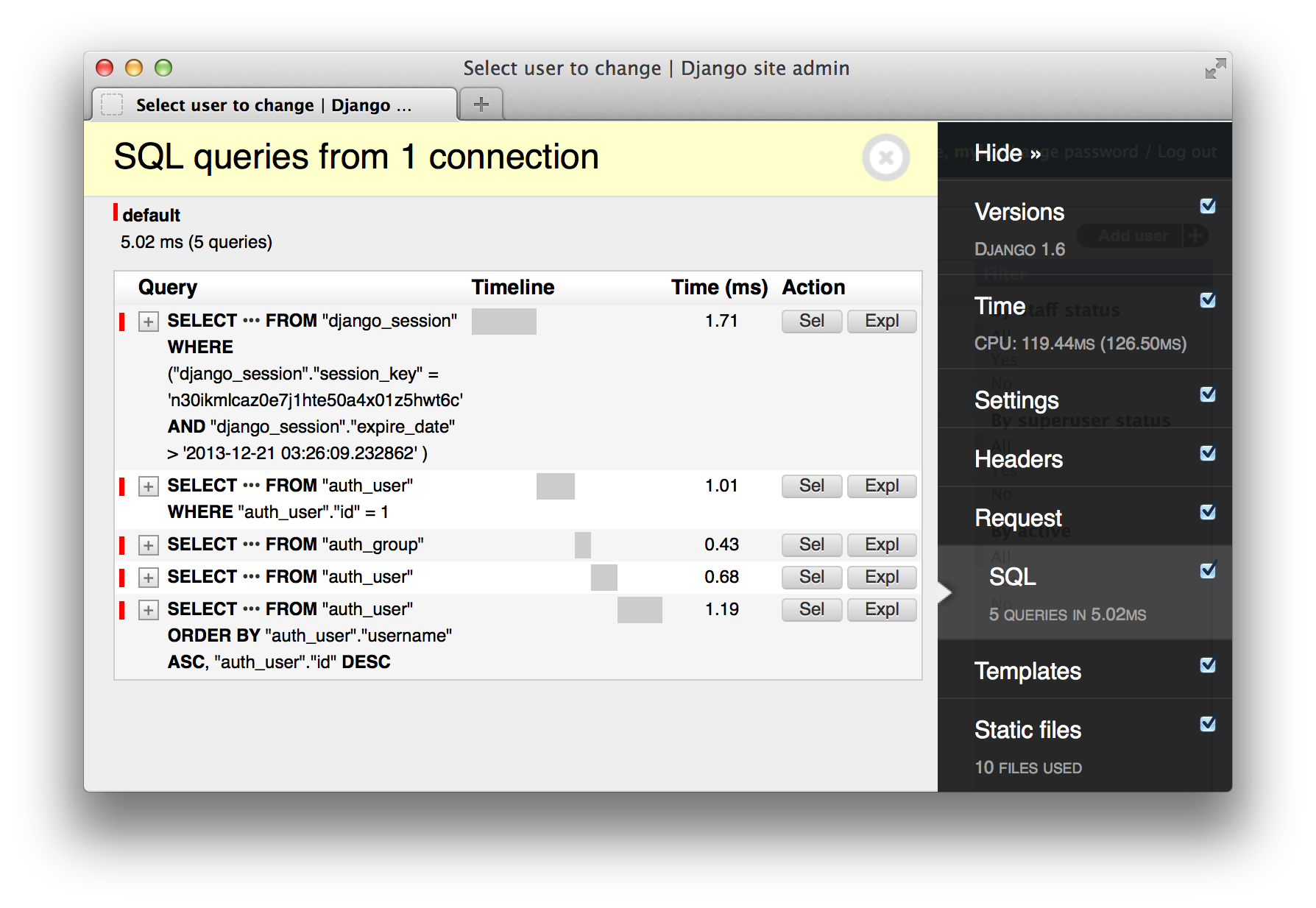
One issue with Debug Toolbar is that it doesn’t work on AJAX or non-HTML
requests. django-debug-panel[4] is an add-on that works around the
limitation by displaying the Debug Toolbar in Chrome’s web inspector with the
help of a browser plugin.
If you prefer working in a console, you may find django-devserver[5] more
to your liking. It is a runserver replacement that will show you similar
information, but dumped out to the console instead of the browser.
Whichever tool you choose, the information you want to get at is the same. In order to efficiently optimize your code, you need quick answers to the following questions:
How long did it take to serve the page?
How many SQL queries ran?
What was the cumulative time spent in the database?
What individual queries ran and how long did each one take?
What code generated each query?
What templates were used to render the page?
How does a warm/cold cache affect performance? Hint: use your settings to toggle the cache
Where to Optimize
Database Optimization
In almost every dynamic web application, the database is the performance bottleneck. It frequently needs to access information from the disks (the slowest part of a modern computer) and performs expensive in-memory calculation for complex queries. Minimizing both the number of queries and the time they need to run is a sure-fire way to speed up your application. We can attack this problem from a number of different angles, and there are usually a lot of low-hanging fruit for easy optimization. The following recommendations are presented from easiest to most difficult. You can work your way down the list until you reach your desired efficiency.
Reduce Query Counts
Django’s ORM makes it trivial to query and retrieve information from your database. A side effect is that it hides a lot of complexity, making it easy to write code that triggers lots and lots of queries. Even a seemingly innocuous template change can add tens (or even hundreds) of queries to a single response. In a complex application, it’s easy to build a view which makes hundreds or even thousands of queries to the database. While you might be able to get away with this on a low-traffic site, pages like this are a no-go on high-traffic sites. They’ll crush even the beefiest database server under moderate traffic.
The good news is that by leveraging some of the advanced features of Django’s ORM, it’s usually possible to drop that number to 20 queries or less.
The first and simplest reduction is to look for places where select_related
and prefetch_related can be used. These queryset methods come in handy
when you know you’ll be traversing foreign key relationships after the initial
lookup. For example:
# one query to post table
post = Post.objects.get(slug='this-post')
# one query to author table
name = post.author.name
This code makes two queries to the database. Once to fetch the post and another
to fetch the author. A select_related can halve the queries by fetching the
author object during the initial lookup.
post = (Post.objects.select_related('author')
.get(slug='this-post'))
Saving one query isn’t a big deal, but these queries usually stack up. Let’s look at the following view and template:
post_list = Post.objects.all()
{% for post in post_list %}
{{ post.title }}
By {{ post.author.name }}
in {{ post.category.name }}
{% endfor %}
This will do two queries on every loop iteration (author and category). In a list of 20 posts, we can drop the queries from 41 to 1:
post_list = (Post.objects.all()
.select_related('author',
'category'))
This will use SQL JOINs to lookup all the necessary data in a single query.
There are rare scenarios where a JOIN will be more expensive than multiple
queries so make sure you are keeping an eye on the total SQL time during this
process. If you drop a couple queries, but your overall time goes up,
it’s probably better to keep the extra queries. The only caveat is that a
database round-trip over the network in production is probably longer than
localhost on your laptop.
select_related has a complementary method, prefetch_related which will
allow you to do lookups in the other direction (getting all parents for a given
child). The ORM can’t collapse these lookups into a single query, but it will
still result in a massive reduction in the overall query count.
Django’s documentation on both select_related and prefetch_related is
great and worth a review if you’re feeling a little fuzzy on the subject:
https://docs.djangoproject.com/en/dev/ref/models/querysets/#select-related
https://docs.djangoproject.com/en/dev/ref/models/querysets/#prefetch-related
All of a view’s queries are available in the SQL panel of Django Debug
Toolbar. You can use it to identify places where a related lookup will help.
Look for repeated queries that take the form of a SELECT with a WHERE
clause on id. For example:
SELECT ... FROM blog_author WHERE id=8;
Simply track this query back to its source and sprinkle a select_related on
it to make a huge dent in your total query count.
Sometimes, however, you’ll add a prefetch_related method and the additional
queries don’t go away. Instead, you’ll end up adding a query. Two things could
be working against you in this case. First, make sure you aren’t doing the
additional lookups manually:
post = Post.objects.get(slug='this-post')
author = Author.objects.get(pk=post.author_id)
You’ll also see this if you are putting additional filtering on the related queryset. For example:
post = (Post.objects.prefetch_related('tags')
.get(slug='this-post'))
# no extra queries
all_tags = post.tags.all()
# triggers additional query
active_tags = post.tags.filter(is_active=True)
In some scenarios it will be cheaper to take advantage of the cached query and do the additional filtering in memory:
active_tags = [tag for tag in all_tags if tag.is_active]
Also note the Prefetch object[6] added in Django 1.7 which gives you even
more control over how prefetch_related works by letting you perform
additional filtering on the related query.
While you are reviewing your queries, make sure all the queries are actually needed to render the view. Over time, it’s possible to accumulate queries that aren’t even used. Take this opportunity to axe them.
In general, this is easy work and on an un-optimized code base, this technique can help you drop well over 50% of the total queries.
Reduce Query Time
Once we have as few queries as possible, we want to make the remaining queries faster. Django Debug Toolbar comes to the rescue again. It will show us the slowest queries for any given page.
When you see a query that stands out as slow (greater than 50ms), check for the following issues:
Missing Index
Adding indexes to a table is trivial, but figuring out where to add them can be a little challenging. If you’re working with a really small dataset locally, you’ll never see the issue because your RDBMS can scan the table quickly. This is one good reason to test with data that approximates what you have in production.
The main place a missing index will hurt performance is when the WHERE
clause is used on a non-indexed column on a large table. Use the EXPLAIN
statement to get some insight into what’s happening under the hood. Django
Debug Toolbar makes this accessible to you with the click of a button in the
SQL panel. EXPLAIN output tends to be pretty verbose and complex, but
there are a few simple clues you can look for.
In PostgreSQL, you are looking for places that Seq Scan is used instead of
Index Scan and the “actual” rows is a really big number. In MySQL, look for
places where the key and possible_keys columns are NULL and
rows is a really big number. In both these scenarios, you can probably make
gains by adding an index on the column(s) referenced in the WHERE clause.
To add the index, simply add db_index=True to the field’s definition in
models.py.
If you frequently filter on multiple columns together, the
index_together[7] model Meta option can be a huge improvement as well.
Just remember, however, that the ordering matters. Your index needs to be
in the same order the fields are referenced in your SQL and filters otherwise
your database can’t use it.
Tip
It’s a very common mistake to add the index locally, but forget to apply it to remote environments (production, staging, etc). Make sure to create a migration when you add an index so it is automatically applied to any remote environments as well.
In most cases, adding column indexes is an easy performance win. There are a few caveats though. First, test and verify that adding the index actually makes the query faster. In some cases, the database’s query planner will not use an index if it can perform the query faster by other means. You should see an immediate drop in the query time once the index is added. Also keep in mind that indexes are not free. They need to be updated on every write to the database. If you have a write-heavy application, you’ll want to investigate the performance impact. On read-heavy loads, adding the index is almost always a win.
Expensive Table Joins
Joins aren’t inherently bad, but sometimes they can result in very poor
performance. If you see a slow query with a large JOIN clause, see if you
can rewrite it so fewer joins are necessary. It usually requires some trial
and error to find the ideal query structure, so don’t be shy about opening up
a console and testing the raw SQL. Use the timing flag in Postgres and
profiler in MySQL to see the query times. In some cases, two queries may
perform much better than one; you can get the ids from the first
query and pass them into the second query:
tag_ids = (Post.objects.all()
.values_list('id', flat=True)
.distinct())
tags = Tag.objects.filter(id__in=tag_ids)
Too Many Results
Be careful not to run unbounded queries. It’s easy to have a .all() that
works fine on your development machine, but against a production database
returns thousands of results. Limit your queries using queryset[:20] (where
20 is the maximum results returned) or use pagination where appropriate.
Counts
Database counts are notoriously slow. Avoid them whenever possible. A common cause is Django’s pagination, but custom paginators are available that don’t require a full page count. In many cases, it isn’t important to know the exact number of objects and the query can be avoided.
Another common source of counts is the anti-pattern:
posts = Post.objects.all()
if posts.count() > 0:
# do something
Change these to use the much more performant .exists():
posts = Post.objects.all()
if posts.exists():
# do something
If all you need is an approximate count, there are a few hacks to get a recent (but not current) count out of the database without incurring the overhead. Take, for example, the following query in Postgres:
db=# \timing
Timing is on.
db=# SELECT COUNT(*) FROM image_thumbs;
count
--------
479099
(1 row)
Time: 8391.118 ms
db=# SELECT reltuples FROM pg_class
db=# WHERE relname = 'image_thumbs';
reltuples
-----------
475981
(1 row)
Time: 112.018 ms
That’s a whopping 98% reduction in query time for a count that, in this case, is accurate within 1%. How about a similar technique in MySQL?
db> SELECT count(*) FROM image_thumbs;
+----------+
| count(*) |
+----------+
| 2759931 |
+----------+
1 row in set (2.15 sec)
db> SELECT table_rows FROM information_schema.tables
-> WHERE table_schema = DATABASE()
-> AND table_name="image_thumbs";
+------------+
| table_rows |
+------------+
| 2843604 |
+------------+
1 row in set (0.10 sec)
The accuracy you’ll get from these will vary, but in many cases, after a few hundred records, the exact number is not important and a rough estimate will do.
Generic Foreign Keys
Generic foreign keys are a really cool feature in Django that lets you link arbitrary objects together and easily access them via the ORM. Unfortunately for optimization, they unleash some nasty queries on your database to make it all work. Whenever possible, just avoid them. If for some reason you can’t, keep in mind they will probably be an area that requires heavy caching early on.
Expensive Model Methods
A common MVC practice is to build “fat models” that have methods for frequently used properties on an object. Often these methods do a number of database queries and package them up as a single property that is convenient for re-use elsewhere. If the properties are accessed more than once per request, you can optimize them with memoization[8]. The nice thing about this technique is that the cache only lives for the length of the request/response cycle so you’re well protected from issues with the data becoming stale. Here’s a simple example:
from django.utils.functional import cached_property
class TheModel(models.Model):
...
@cached_property
def expensive(self):
# expensive computation of result
return result
Results Are Too Large
For many applications, the cost of shipping the bits from your database to your
application server is trivial. If, however, your models have fields that store
sufficiently large amounts of data, it could be slowing down the transfer.
Django provides a few queryset methods to work around this. defer and
only return model objects while values and values_list return a list
of dictionaries and tuples, respectively.
# retrieve everything but the `body` field
posts = Post.objects.all().defer('body')
# retrieve only the `title` field
posts = Post.objects.all().only('title')
# retrieve a list of {'id': id} dictionaries
posts = Post.objects.all().values('id')
# retrieve a list of (id,) tuples
posts = Post.objects.all().values_list('id')
# retrieve a list of ids
posts = Post.objects.all().values_list('id',
flat=True)
Tip
values and values_list bypass the process of initializing your
Python model objects altogether. If you never intend to access methods or
related fields, these methods are going to be more efficient and can shave
off some unnecessary Python processing time.
Query Caching
The next place to look for performance gains is to remove duplicate queries via caching. For many workloads, a generic query cache will give you the biggest gains with the lowest effort. A query cache effectively sits in between the ORM and the database storing, fetching, and invalidating its cache automatically. Custom caching code is going to be more efficient, but it comes at a cost.
Humans have to write it. Humans are expensive and error-prone.
Cache invalidation is one of the hard problems in computer science.
There are a couple of good (well-tested, well-used) options in the Django ecosystem including Johnny Cache[9] and Cache Machine[10]. We found Johnny Cache to be the easiest to implement and it has proven stable for us under heavy workloads.
Johnny Cache appears pretty magical at first so its worth understanding what’s happening under the hood (a good practice in general).
Johnny Cache works via a custom middleware. This middleware captures requests and puts the results of any database reads into the cache (Memcached or Redis). Future requests will check for queries stored in the cache and use them instead of hitting the database. Those queries are cached forever and key-based invalidation is used to keep it fresh. If Johnny Cache intercepts a write to a specific table, it updates a key invalidating all the cached queries for that table. It’s a heavy-handed approach, but it guarantees your cache hits are always valid. Not having to worry about cache invalidation is a good thing.
Astute readers may have identified a problem with this approach – it is tied
to the request/response cycle. One-off scripts, management commands, and
background tasks won’t invalidate the cache by default. Luckily, that can be
fixed by adding this to your project’s __init__.py:
import johnny.cache
johnny.cache.enable()
This is the dividing line between the low hanging fruit of database optimization and the bigger guns. Make sure you’ve reviewed everything above this line before going any further. It’s possible to handle massive amounts of traffic without any more special tricks. But if you’re in a situation where the database still can’t keep up, the following techniques may help. They’re more work but can be effective for heavier workloads.
Read-only Replicas
If your workload is read-heavy, adding more database servers can help distribute the load. Add a replica by using the replication mechanisms provided by your database. Django’s multi-database and router support[11] will let you push all (or some) read traffic to the replica database.
Raw Queries
Django’s ORM is flexible, but it can’t do everything. Sometimes dropping to raw
SQL can help you massage a particularly poor performing query into one that is
more performant. Look into the raw method, or executing custom SQL, in the
Django docs[12].
Denormalization
For joins that are a necessity, but too slow or not possible, some columns can be copied from the source table to the table needing the join. Effectively, this is caching data inside the database and along with it come all the typical caching problems. Writes for that table are now doubled because they need to update every table that includes a denormalized field. Additionally, extra care needs to be taken to make sure that all the values stay in sync.
Alternate Data Stores
We are big fans of the RDBMS. They are well suited for many different workloads and have first-class support in Django. With Postgres’ hstore/json support[13], you can even do schemaless data better than many “NoSQL” data stores[14].
There are scenarios, however, where an alternative database can complement an RDBMS acting as the primary storage. The most common example of this is pushing data into Elasticsearch or Solr for their full-text search capabilities. Another NoSQL database you’ll find hiding behind many high performance sites is Redis. Not only is it incredibly fast, but it also offers some unique data structures that can be leveraged to do things that are difficult or expensive in a RDBMS. Here are a couple write-ups that provide good examples of Redis complementing a RDBMS:
Tip
Adding services in production isn’t free. As developers, we often overlook this, but systems require support, configuration, monitoring, backup, etc. Keep in mind the maintenance burden and always think of your sysadmins!
Template Optimization
Django templates are the second biggest pain point in the stack. Switching to Jinja2 is an option for faster rendering. It will alleviate some of the pain, but also bring some new challenges and even with Jinja2, it’s likely template rendering will still be the second slowest part of your stack. Instead we use caching to remove as much of the template rendering as possible from each response.
Russian Doll Caching
A favorite technique of ours, Russian doll caching, received some attention in the Ruby on Rails world due to a blog post from Basecamp founder, David Heinemeier Hansson[15]. The concept works very well in Django too. Basically, we nest cache calls with different expirations. Since the whole template won’t expire simultaneously, only bits and pieces need to be rendered on any given request.
In practice it looks something like this:
{% cache MIDDLE_TTL "post_list" request.GET.page %}
{% include "inc/post/header.html" %}
<div class="post-list">
{% for post in post_list %}
{% cache LONG_TTL "post_teaser_" post.id post.last_modified %}
{% include "inc/post/teaser.html" %}
{% endcache %}
{% endfor %}
</div>
{% endcache %}
First, you’ll notice the MIDDLE_TTL and LONG_TTL variables there. We
pre-define a few sensible cache timeout values in the settings and pass them
into the templates via a context processor. This lets us tweak the caching
behavior site-wide from a central location. If you aren’t sure where to start,
we’ve been happy with 10 minutes (short), 30 minutes (middle), one hour
(long), and 7 days (forever) on read-heavy, content-driven sites. On very
high-traffic sites, even much lower values will relieve burden from your app
servers.
The Russian doll technique comes in as we nest these calls from shortest expiration to longest expiration. The outside of the loop will expire more frequently, but it will not need to fetch every item in the loop on expiration. Instead, all of these will still be cached and fast.
Next let’s analyze how the cache keys are built. On the outside cache fragment,
we include the page number that was passed in as a URL parameter. This ensures
the list is not reused across each page where the cache is used. Another thing to
consider for object list caches is any filtering that is done on the list
between pages (but sharing the same template). You may need to include a
category.id or some other distinguishing characteristic.
The inner cache key uses key-based expiration. This is a great way to handle the difficulty of cache invalidation. We timestamp our models with a last modified date that gets updated on save, and use that date in our cache key. As long as the date hasn’t changed, we can cache this fragment forever. If the date changes, Django will look for the object at a different cache key and miss, re-caching the object with the new key. There isn’t a risk of overflowing the cache because “least recently used” (LRU) keys are flushed if additional space is needed.
Custom Cache Template Tag
Django ships with a basic cache template tag, but we want some additional
functionalities, so we often extend it with our own custom tag.
First, we want a convenience method to invalidate and reset all the cached HTML fragments for an entire page. This is a lifesaver for supporting your editorial team on publishing websites and is a big help to developers/support/admins when they are called to troubleshoot. Instead of telling them to wait and refresh the page in 1/5/20 minutes when the cache expires, they can simply generate a “fresh” page by appending a magic query parameter to the URL. You can even hit this magic URL from directly within your code to do a proactive cache flush in response to specific actions in your application.
Here is the relevant snippet to handle the invalidation:
class CacheNode(template.Node):
bust_param = 'flush-the-cache'
...
def needs_cache_busting(self, request):
bust = False
if request.GET and (self.bust_param in request.GET):
bust = True
return bust
def render(self, context):
...
value = cache.get(cache_key)
if self.needs_cache_busting(request) or value is None:
value = self.nodelist.render(context)
cache.set(cache_key, value, expire_time)
return value
Another issue you’ll encounter is the simultaneous expiration of multiple cache keys. When you throw a bunch of content into cache with the same timeout, it is all going to expire at the same time. Over time, the problem tends to get worse as expiration times start to synchronize. Your cache server ends up on a roller-coaster doing lots of sets at repeating intervals, resulting in the thundering herd problem[16]. This can be mitigated by applying jitter to your cache expiration times. Here is a simplified example to apply a +/-20% jitter:
def jitter(num, variance=0.2):
min_num = num * (1 - variance)
max_num = num * (1 + variance)
return randint(min_num, max_num)
A full version of the custom template tag code can be found as a Gist on GitHub.
Do Slow Work Later
Never do today what you can put off till tomorrow.
—Aaron Burr
Getting Django views to complete in less than 200ms doesn’t leave a lot of overhead for extra computation. Modern web applications commonly have views that need to make calls to external services or perform heavy-duty processing on data or files. The best way to make those views fast is to push the slow work to a job queue. In the Python world, Celery is the job queue of choice. Simpler ones exist, but beyond a certain scale, Celery should be the one you reach for since you’ll probably want some of its more advanced features.
Celery requires a separate message queuing service to transport job information from your application to the workers. For low volumes, Redis is good enough to act as a queue service and, if it’s already in use, helps keep your infrastructure simple. For sites with more intensive needs, RabbitMQ tends to be the queue of choice.
Good candidates for background tasks that can be pushed to Celery are:
Third-party API calls
Sending email
Heavy computational tasks (video processing, number crunching, etc.)
In some cases, you’ll want to prioritize jobs. Tasks that have a user waiting for a result are more important than run-of-the-mill system maintenance tasks. For these scenarios, it makes sense to split your work into multiple queues. Jobs on your high-priority queue should be picked up immediately, while it’s ok for your low-priority queue to wait from time to time. This is easy enough to accomplish by modifying the number of workers assigned to each queue or the size of the servers that house those workers. It is one of the other places where auto-scaling can come in handy.
A couple tips on structuring your tasks:
Do not use stateful objects such as models as arguments to the tasks. This reasoning is twofold. One, you don’t know when the task is going to execute. There is a risk of the database changing by the time a model object is picked up by a worker. It’s better to send a primary key and fetch a fresh copy of the object from the database in the task. The other reason is the serialization process required to push the task and its arguments on the queue. For complex objects this process can be expensive and a source of problems.
Keep your tasks small and don’t hesitate to have one task trigger more tasks. By breaking up long-running jobs into small atomic tasks, you can spread them across more workers/CPUs and churn through them faster. (There is some overhead to creating tasks, so don’t go too crazy here.) Another benefit is that you can quickly restart and kill-off worker processes safely. A worker will not gracefully stop until is has completed its current task so keeping tasks small will make your deployments faster.
Warning
If you are creating an object in the database and then immediately creating a task that depends on it, you can get into a race condition between the the database transaction committing and the task getting picked up by an available worker. If the worker wins, your task will fail. This can be worked around by delaying the task execution for a few seconds or the django-transaction-hooks[17] library.
For tips on advanced Celery usage, Daniel Gouldin’s talk, Using Celery with Social Networks[18] from DjangoCon 2012 is a great resource.
Scheduled tasks are another opportunity to cut back on hefty views. Good candidates for scheduled tasks are administration reports, cleaning up dead records in the database, or fetching data from third-party services. Since we’re already using Celery, the “beat” functionality [19] is a good option to manage these tasks.
Celery beat lets your developers easily add new scheduled tasks with Python
functions and Django settings instead of building out custom management
commands. Defining cronjobs usually requires a context switch to the
configuration management tools, or worse, manually setting it up on a server
and then forgetting about it. Additionally, Celery has support for things that
cron does not like - retrying failed tasks and finer grained schedules.
Finally, you should already be monitoring Celery tasks for failures, so your periodic task monitoring is already there.
For stacks that aren’t already using Celery or aren’t sold on the benefits,
good ol’ Unix cron is certainly a viable option.
Front-end Optimizations
It’s easy to get lost in the performance of your back-end services, but important to remember that they only paint one piece of the end-user’s experience. We’ve seen Django sites that can render pages in less than 200ms on the back-end, but require 7 seconds to load into the browser. Entire books have been written on the topic of front-end performance[20], so we’ll just hit the topics that overlap with Django.
To measure your front-end performance and see where it can be improved, look at YSlow[21] and Google’s PageSpeed[22]. They are both offered as browser plugins that give you immediate data on page load similar to Django Debug Toolbar.
Minimizing CSS & JavaScript
In some ways, you can think of CSS and JavaScript files like database queries:
Fewer is better.
Smaller is better.
They should be cached whenever possible.
To make this happen, you’ll need a tool that can collect, concatenate, minify, and version your static files. The result is a payload that not only small and fast over the wire, but can be cached forever in the browser.
A number of solid libraries in the Django ecosystem are up to handling this
task including django-pipeline[23], django-compressor[24], and
webassets[25]. Our current preference is Pipeline. It provides all the
necessary functionality and doesn’t add any significant overhead to the
template rendering.
If your site has a large JavaScript code base, it may make more sense to relegate this task to front-end build tools where you can take advantage of tools like Require.js[26] or Browserify[27].
Warning
The Django libraries all include versioning (usually as unique filenames for each build) to ensure your visitors’ browsers don’t use stale cached versions. If you choose a JavaScript solution, make sure the output is versioned before it lands on your production servers or CDN.
Compress Images
People put a lot of focus on JavaScript and CSS optimization, but often it only shaves a few kilobytes off of the first page load. In contrast, photo-heavy sites can save megabytes per page load by optimizing their images and thumbnails.
Static assets are easy enough to optimize locally via pngcrush or similar
tools prior to checking them into version control. If your users are uploading
images, that’s another story. As part of your thumbnailing process, consider
running them through an optimizer like the one included in
easy-thumbnails[28]. It’s not uncommon to cut down the size by 50% or
more with this technique.
Serve Assets from a CDN
Leveraging a CDN like those provided by Amazon Cloudfront or Rackspace/Akamai is not only going to improve performance for your end-users, but also reduce traffic and complexity on your servers. By pushing these assets to a CDN, you can let your servers focus on serving dynamic data and leave static files to your CDN.
Getting files into your CDN isn’t always a straightforward process, however.
Some of the static file compression tools like django-compressor and django-pipeline already
support custom storage backends, while others will require extra steps to get
your files to a CDN. Another approach is to serve your static files directly from your app servers and set it up as a dynamic origin for your CDN (Amazon Cloudfont has this capability). There are a number of options for static file serving in your stack including uWSGI[29] and WSGI middleware[30].
Third-party storage back-ends also exist that will let you send files directly to your CDN, but that comes with its own challenges.
File Uploads
With a single app server, uploading files is a pretty trivial process. You can store, manipulate, and serve them from the server’s filesystem. Once you start adding app servers, however, this approach becomes problematic. You can create a shared volume via NFS or use something more robust like GlusterFS or Ceph, but for most sites, commercial offerings like Amazon S3 or Rackspace Cloud Files are going to be easier and relatively inexpensive options. As a bonus, they’ll serve your files over HTTP as part of the package.
Once file uploads are moved off the local disk, manipulating them (e.g. thumbnailing or optimizing images) becomes painfully slow. The server needs to download the image from the remote storage, manipulate it, then upload the result. On a page with 20 thumbnails, these network round-trips add up quickly and kill performance.
We take a two-fold approach to this problem. Common operations are predefined and done upfront. In the common case of image thumbnails, we define all the common sizes in the Django settings. On upload, task(s) are sent to Celery to pre-generate and upload those thumbnails in the background. As a failsafe, we maintain the ability for thumbnails to be generated on-the-fly from a template tag. This ensures users will never see broken thumbnails in the event of the first request happening before the queued task completes.
Testing
A good test suite is a strong indicator of a healthy code base. It lets your team deploy with confidence instead of nerve-wracking scrambles to fix unexpected regressions.
Our approach to testing is pragmatic; we don’t buy wholesale into any one particular philosophy. The priority is to get test coverage on the parts of your code that are the most difficult, most important, and most likely to break. 100% test coverage is a valiant goal, but it doesn’t guarantee your code is bug free and is rarely an efficient use of development time.
Automated Testing and Continuous Integration
Tests are only good when they run and when developers know if they fail. Early on in your development process, you should have a continuous integration system in place that will run automated tests and health checks on your code base to ensure it’s in good shape.
We typically use Jenkins CI to run a number of checks on our code. Depending on the project, they may include:
Unit tests
Code coverage
PEP8/Linting
Functional tests via Selenium
Performance tests via Jmeter (discussed in Load Testing with Jmeter)
django-jenkins[31] can help you get your project working with
Jenkins quickly. It handles outputting unit test results in a format Jenkins
can understand as well as providing coverage, pylint, and flake8
functionality.
Tip
Testing services such as Travis CI are growing in popularity and make it simple to get started with continuous integration. As with any hosted service, you may be trading off a significant amount of flexibility for what types of data you can capture and how it is displayed.
So far, we’ve showed you how to get your site built and running efficiently, but that’s only half the battle. Launching a high performance Django website is impossible without a good server infrastructure. In the next section, we’ll discuss the production deployment – moving the code off your laptop and onto well-tuned servers.