

This post was created as a collaboration between Lincoln Loop and Maciej Fijalkowski from baroquesoftware.com.
In the space of web architecture, the prevalent belief states that “database based applications are I/O bound”. While this might have been true in the past, two developments have highly encroached on that. First, memory has been getting bigger and bigger—minimizing the need to access the HD. Second, the database connection layers have been getting increasingly sophisticated—putting more and more pressure on the CPU.
For CPU bound Python applications, using PyPy instead of the traditional CPython interpreter can provide massive improvements (5x or more is common).
In this post we examine how PyPy can improve the Django ORM’s execution times. We built a set of benchmarks using some “simple” queries with the Django ORM. These let us analyze PyPy’s performance and warmup stats. Finally, we want to present some future developments to improve the current situation.
Let’s start with the benchmark description - it’s a simple set of queries that were distilled from the BotBot IRC logging system. The original source can be found on GitHub. There is really nothing fancy, just a series of queries to a SQLite database. BotBot uses Postgres in production, but here we’re only interested in the CPU overhead of calling into the DB, which was bigger than the cost of DB operations itself.
For the first step let’s compare PyPy performance vs CPython performance. We run the queries in sets of 100 and measure the time each set takes using simple wall time. The y axis on the plot is the request time in ms, the x axis on the plot is number of CPU seconds since the start.
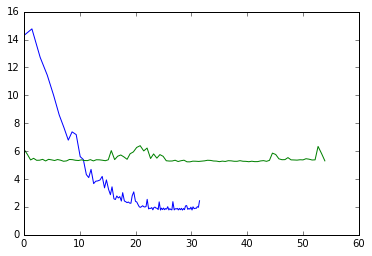
We can adjust the plot to see how much time it takes for a single request to finish:
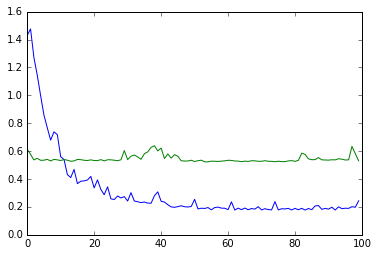
We can see that PyPy (the blue line) starts slow (about 3x slower than CPython) and gets up to 3x the speed of CPython (the green line). This was done on my Macbook, on a Linux machine which has more optimizations, it goes to about 4x CPython speed. This behavior is expected as PyPy’s JIT needs time to optimize the code paths or “warm-up”.
Now we look into the profiles themselves. I’ve run pypy -m vmprof --web query2.py for 1,000 10,000 100,000 runs. As we can see below, the red/yellow (interpreter/warm-up) goes away in favor of green (JIT), quite consistently.
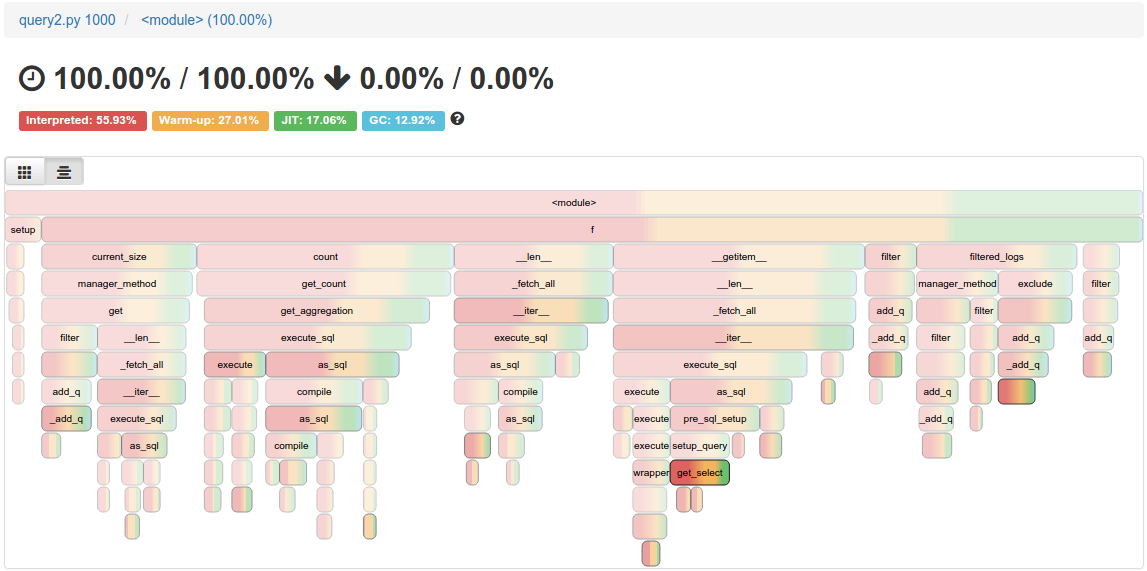
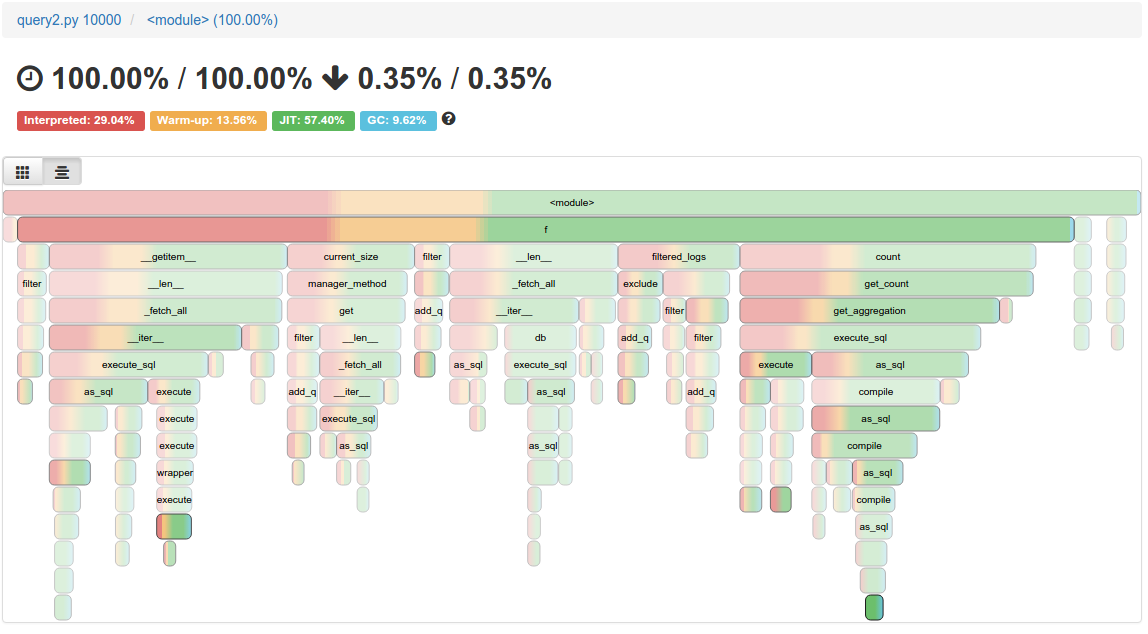
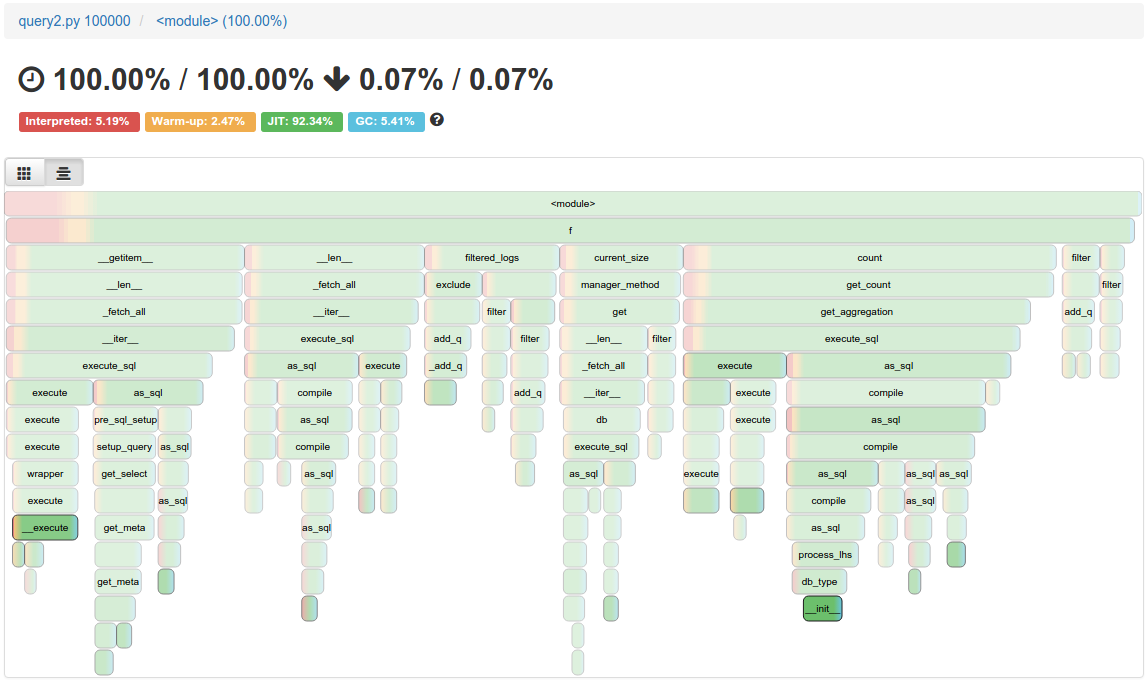
The outcome is pretty good, but definitely not ideal. We would love to see Django-based websites start fast as soon as possible. I managed to isolate the code responsible for slower than usual warm-up time, and it would look roughly like this if we generalized it to pure-python code that exemplifies the problem in PyPy:
class A(object):
def method(self):
pass
class B(object):
def method(self):
pass
class C(object):
def method(self):
pass
class D(object):
def method(self):
pass
choice = [A, B, C, D]
def f(i):
l = []
l.append(choice[i % 4]())
l.append(choice[(i >> 2) % 4]())
l.append(choice[(i >> 4) % 4]())
l.append(choice[(i >> 6) % 4]())
l.append(choice[(i >> 8) % 4]())
return l
import sys
for k in range(int(sys.argv[1])):
l = f(k)
for elem in l:
elem.method()
Some equivalent code in Django, would be the SQL generation at the end of the ORM’s pipeline. It executes the same code, but calls it with different classes each time, which results in a new JIT code for each combination of parameters.
We see three ways how we can approach this problem:
- No silver bullet, make PyPy’s warm-up faster. This is a bit tricky, given the peculiarities of the problem, but certainly feasible. We’ve been working a lot on that recently and expect PyPy 4.1 and 4.2 to be better at warm-up performance than ever. That approach would have a benefit of helping not just Django.
- Optimize Django’s ORM. Django compiles the SQL for each call to the ORM. It would be very cool if we can build “templates” so ORM queries are just “fill these gaps in with values” with everything else pre-built. As we can see on vmprof, the compiler is still a significant percentage of the total time, which can be completely cut off if the ORM was a little smarter. As a beginning, I would suggest a package that does something like this:
# global scope
t0 = Variable("timestamp0")
t1 = Variable("timestamp1")
query = Channel.filtered_logs().filter(timestamp__gte=t0, timestamp__lt=t1)
def f():
# query scope
...
query.bind(timestamp0=start_date, timestamp1=end_date)
and maybe that can be done in a completely transparent manner. This approach would help Django performance immensely on both PyPy and CPython.
- Silver bullet - save PyPy’s JIT traces to the hard-drive, so they’re preserved across runs. This is a difficult approach that we’ve been toying with in the past, and has been stalled due to lack of funding.
- Pre-warm the applications. Add a small hook that hammers the ORM for about 30s at the start of each worker. Not ideal, but a very easy thing to pull off.
Summary
PyPy seems to be doing quite well on the Django ORM front, but starts as much as 3x slower than CPython for the first 1,000 queries or so. If you have tons of processes serving different sites with just a few queries a day - then you would definitely not benefit from using PyPy for the CPU budget (you might still benefit on memory, but it’s outside of the scope of this post). However, once we start looking into thousands of queries being processed by each worker it is definitely very useful. One important thing to note is that if you recycle your worker instance every 1,000 requests or so, PyPy will not be able to help you.
In short, if you operate a high-traffic site that is CPU-bound, switching to PyPy may significantly improve response times and potentially reduce your hardware requirements by reducing overall CPU usage.